1 概念
(1) 定位
是一个基于Hadoop的数据仓库基础设施。Hadoop提供海量数据存储和处理能力,以及容错机制。
Hive被设计用来简化数据综合、海量数据临时查询和分析,可以整合SQL和用户自定义函数。
(2) 限制
不适用于在线事务处理。
(3) 数据单位
根据粒度从大到小如下:
1) 数据库
命名空间,用于防止命名冲突,以及分离用户或用户组安全机制。
2) 表
具有相同模式的数据集合。
3) 分区
用于对每张表进行分区,非必需。
用户可根据分区标准选择性地执行查询任务,提高效率。
分区不是数据的一部分,但在数据加载时获取。用户需要自行保证分区标准的严格执行。
4) 桶(或群)
用于高效抽样,非必需。
在每个分区内,基于哈希函数分组的数据。
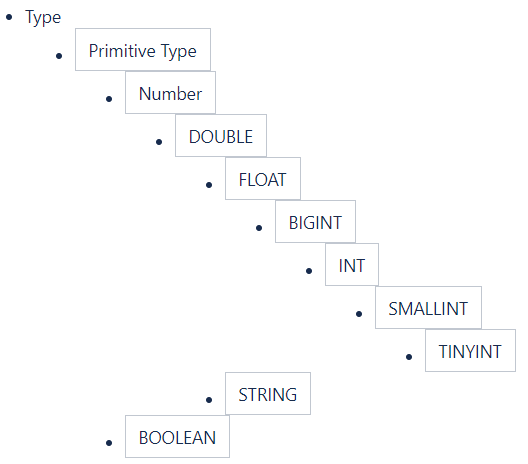
(5) 类型系统
1) 基本类型

隐式类型转换:
显式类型转换详见Built In Functions
2) 复杂类型
复杂类型可由基本类型和以下组合方式构成:
Structs
结构中的数据通过句点访问。如STRUCT {a INT; b INT}类型的c中,使用c.a访问a
Maps
映射表使用方括号访问。如映射表M中获取键名为group的值,使用M[‘group’]
Arrays
数据使用方括号访问。如数组A中第二个元素,使用A[1]访问。
3) 时间戳
LocalDateTime语义
类似于Java中LocalDateTime语义,该时间戳不带有时区信息。解析结果与时区无关。
推荐使用
Instant语义
类似于Java中Instant语义,带有时区信息,解析结果与当前时区有关。
与其他工具比较
| SQL 2003 | Oracle | Sybase | Postgres | MySQL | Microsoft SQL | IBM DB2 | Presto | Snowflake | Hive >= 3.1 | Iceberg | Spark | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| timestamp | Local | Local | Local | Local | Instant | Other | Local | Local | Local | Local | Local | Instant |
| timestamp with local time zone | Instant | Instant | Instant | |||||||||
| timestamp with time zone | Offset | Offset | Offset | Instant | Offset | Offset | Offset | Instant | ||||
| timestamp without time zone | Local | Local | Local | Local |
Other definitions:
Offset = Recording a point in time as well as the time zone offset in the writer’s time zone.
(6) 内部操作符合函数
cast(‘1’ as BIGINT),将字符’1‘转换为BIGINT型,失败则返回null
详见文档
(7) 语言能力
支持基本的SQL操作
2 示例
注意:内容可能过时,最新内容详见LanguageManual